abstract
- 论文基于对抗过程提出了估计生成模型的新框架,主要的做法就是:同时训练2个网络:
G网络和D网络,G网络主要是通过学习获取信息分布,使用隐空间的随机变量生成接近于真实的数据,即使得D网络将生成的数据识别为真实的训练数据;而D网络主要是通过学习,尽可能地区分开真实的训练数据与生成的虚假数据。G网络和D网络都是可微的,因此可以使用BP进行学习。
introduction
- 之前在判别式模型方面已经有很多的研究,比如说分类等任务,但是生成模型由于其最大似然估计和相关策略设置都很复杂,因此目前研究较少,本文则是提出了一种新的生成模型,避免了之前的这些问题。
- 提出的对抗网络中,D网络是通过学习,判断一个样本是由
模型分布(fake)还是有数据分布(real)生成的。G网络则是生成fake samples,使得D网络尽可能混淆真实与虚假数据。 - 论文提出的对抗网络不需要使用markov链,只需要使用BP即可,再结合dropout等tricks。
related work
- 在之前,大部分在
deep generative model上的工作都是希望能够得到一个参数化的概率分布,可以通过最大似然估计进行学习,比较成功的模型有deep Boltzmann machine等。 - 之前比较类似的工作是VAE,即使用encoder将训练数据映射到高斯分布中,再使用decoder将其变换到原始的训练数据,从而实现对数据的参数化分布表示。
adversarial nets
- 这里对GAN进行一个数学的表示,以MLP举例。定义噪声变量$p_z(z)$,表示generator的分布,可以通过映射关系,将噪声映射到对应的
data space,这个映射可以表示为$G(z,\theta _g)$,MLP的参数为$\theta _g$,$G$是可微的(可学习的)。同时定义$D(x,\theta _d)$,输出一个值,$D(x)$表示x来自真实数据而非$p_g$的概率。因此主要的工作就是训练$D$,尽可能使得训练样本和G生成的样品都被赋予正确的label。最终的优化目标是:
$$\mathop {\min }\limits_G {\kern 3pt} \mathop {\max }\limits_D {\kern 3pt} V(D,G) = E_{x \sim p_{data}(x) }[logD(x)] + {E_{z \sim {p_x}(z)}\;}[log(1 - D(G(z)))]$$
属于一个最小最大化的问题,在训练的时候无法先训练好D,再去训练G,因此论文中每训练k steps的D网络,再训练1 step的G网络。具体的训练过程如下:

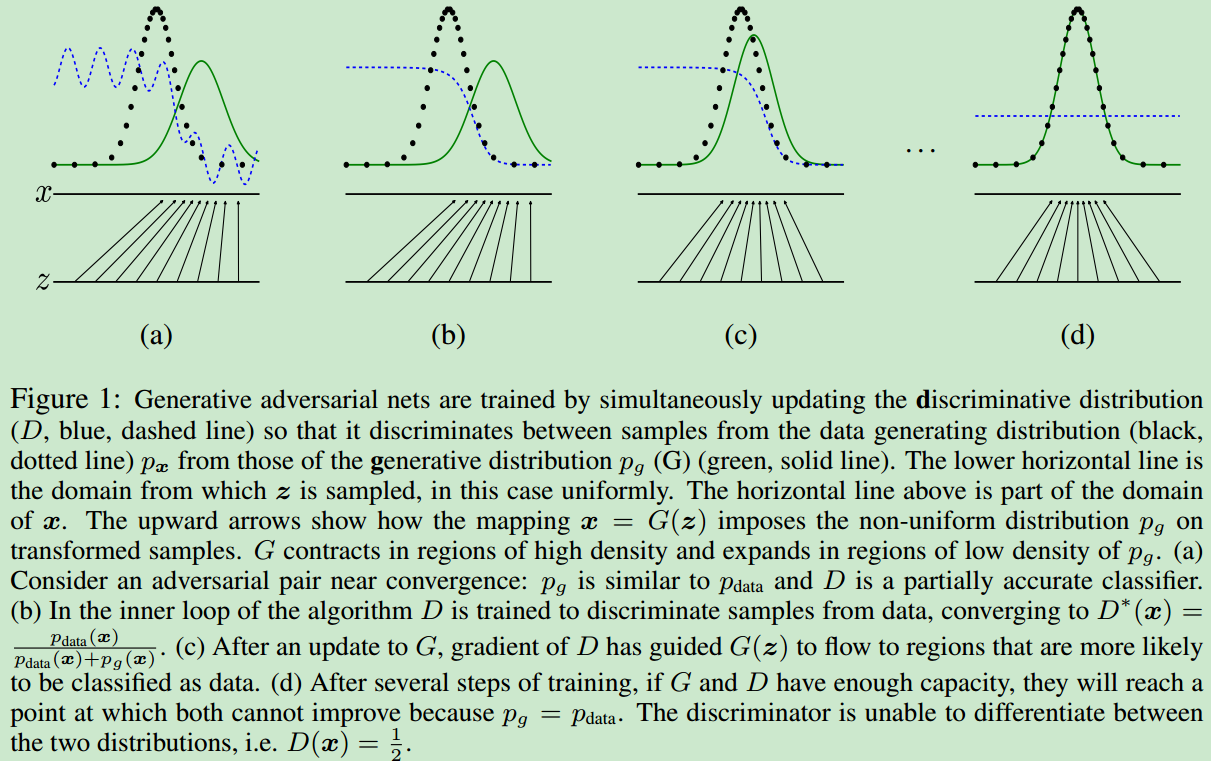
在这里需要注意的是,因为需要最大化D,因此我们使用的是梯度上升法。最终$p_{data}(x)=p_g(x)$,$D(x) = \frac{1}{2}$,在训练的过程中,G和data的分布变化如下
Global Optimality of $p_g = p_{data}$
- 对于固定的G,D的最优解为
$$ D_G^*(x) = \frac {p_{data}(x)} {p_g(x) + p_{data}(x)} $$
具体的证明可以看论文原文,主要就是类似于求$alog(x)+blog(1-x)$的最优解。
Convergence of Algorithm 1
- 如果G和D都有足够的容量,则在每次迭代过程中,D都会到达其最优解,之后在更新G的时候,G都会进行优化,使得$p_g$向$p_{data}$收敛。
Experiments
- 作者在mnist、TFD、cifar-10数据集上进行了实验。对生成的结果基于
Parzen window的似然估计进行评估,在mnist上,相对之前的DBN、stacked CAE等方法,效果更好一些。
Advantages and disadvantages
- disadvantages:没有获得对$p_g(x)$的显性表示,D也必须和G同时训练,共同优化参数,如果只训练其中的一个, 无法获得很好的效果。
- advantages:不再需要markov chains,在训练的时候,直接使用BP即可,并且可以很容易地在模型中嵌入很多其他的函数或者变换。
conclusion and future work
future work
- CGAN,即根据给定的条件和随机分布,生成特定的数据。
- 通过训练一个给定x,预测z的辅助网络,用于样本之间的相似度检测。
- 可以训练一个shared model,给定任意子条件和随机分布,生成该条件对应的样本。
- 半监督学习:当训练数据有限时,可以使用discriminator的特征或者G网络来提升分类器的性能,。
- 在训练的过程中,如果可以确定一个更好的z的分布,则训练速度和模型性能都会大大提升。
conclusion
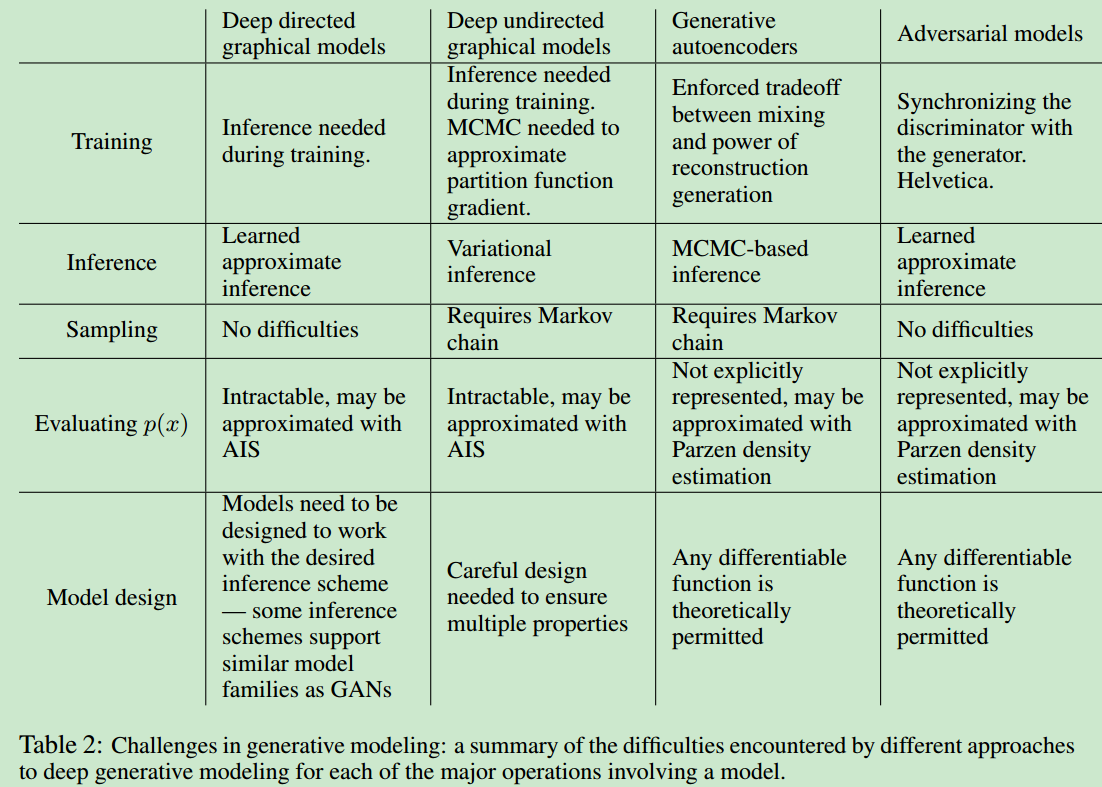
- 一张图总结一下生成模型以及本文的对抗模型,证明了GAN的光明前景。